
¿Y donde esta el perceptrón?
 ¿Te gusto este contenido? Únete a la comunidad de Indie Builders y descubre las mejores formas de crear un producto digital. clic aquí
¿Te gusto este contenido? Únete a la comunidad de Indie Builders y descubre las mejores formas de crear un producto digital. clic aquí Como habrás notado en la semana pasada OpenAI lanzó Images 2.0, un modelo que increíblemente ejecuta instrucciones casi al detalle al momento de generar imágenes. Y para ser honesto, los lanzamientos constantes de modelos de frontera, han hecho que para mí sea casi imposible seguirles el paso.
Entonces preferí regresar a las bases, fui a desempolvar mis apuntes y textos de redes neuronales de mi universidad de pregrado, y me pregunté si los creadores de las frutas infieles estarán conscientes que existe algo llamado el perceptrón, que es la base de la generación de videos, guiones y audios que a muchas personas les gusta consumir, o si los Ingenieros de IA de Instagram sabrán de la existencia de esta unidad de cómputo tan simple (bueno, no tan simple), pero tan poderosa.
Por allá en la década de los 50’s, Frank Rosenblatt propuso una idea algo interesante de transpolar el mundo biológico al mundo de la computación, y su primera exposición fue con el reporte del laboratorio aeronáutico de Cornell llamado “The Perceptron a perceiving and recognizing automaton” donde se esboza al “fotoperceptrón” como un sistema que aprende mediante refuerzo estadístico; un año más tarde propondría la organización de un perceptrón en su obra más popular.

En resumen, un perceptrón puede definirse como la discriminación de una suma promediada, y dicha discriminación es realizada por una “función de activación”:
Donde:
- son las entradas (features).
- son los pesos (cuánto importa cada entrada).
- es el sesgo (bias), un offset que desplaza la decisión.
- es la función de activación, en este caso un escalón unitario.
Puedo mencionar que existe mucha literatura acerca del análisis del perceptrón, y como amante del OCW MIT, me gusta la definición de este recurso, rápida y concisa.
Y hay que tener en consideración la función de activación , ya que me brindará las clases del perceptrón, que comúnmente para temas didácticos se usa el escalón unitario, obteniendo así dos clases y :
El objetivo del método de aprendizaje consiste en obtener los pesos para discriminar las dos clases y . Ahora… ¿cómo se hallan dichos pesos? Es ahí donde se encuentra la experimentación durante todos estos 60 años, suficiente tiempo para que el science’s peak sea crear un personaje llamado “Tralalero Tralala”. Pero para no desviarme del tema, el método clásico es usar el generado por Widrow Hoff, denominado la regla delta de mínimos cuadrados (un caso particular del descenso del gradiente).
¿Recuerdas que había dicho que Frank Rosenblatt mencionaba que el método de aprendizaje era mediante refuerzo estadístico? Pues aquí es donde entra el concepto estadístico.
Frank propone que el error cuadrático medio (MSE) debe converger en 0 o encontrando el mínimo posible (de acuerdo a una tasa de aprendizaje denominada ).
Por lo que se debe implementar una regla de actualización (también llamada adaptación de pesos) para minimizar el error cuadrático en una neurona lineal, y dicha regla es la siguiente:
En resumen se puede sintetizar el proceso en un algoritmo:
PASO 1: Inicializar los pesos y el sesgo con valores aleatorios.
PASO 2: Para cada ejemplo de entrenamiento :
- Calcular la salida del perceptrón .
- Actualizar los pesos y el sesgo usando la regla de actualización.
PASO 3: Repetir el proceso hasta que el error cuadrático medio sea suficientemente pequeño o se alcance un número máximo de iteraciones.
Nota: El perceptrón solo puede aprender a clasificar datos que sean linealmente separables. Si los datos no son linealmente separables, el algoritmo no convergerá.
Para hacerlo interactivo dejaré un visualizador del error cuadrático medio, para que puedas experimentar con los pesos y ver cómo el error converge a medida que el perceptrón aprende a clasificar correctamente.
| i | x₁ | x₂ | y real | z = w·x + b | ŷ = step(z) | (y−ŷ)² |
|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | -1.00 | 0 | 0 |
| 2 | 2 | 2 | 0 | 1.00 | 1 | 1 |
| 3 | 4 | 4 | 1 | 5.00 | 1 | 0 |
| 4 | 5 | 4 | 1 | 6.00 | 1 | 0 |
| MSE = | 0.250 | |||||
Ahora usaremos RUST para poder generar un perceptrón; tomaré un ejercicio de perceptrones del texto “Visión por computador” de Gonzalo Pajares, para implementarlo.
Ejercicio: Suponer una biclase dada a continuación con un , obtener los pesos de conexión y la función de decisión.
Pesos iniciales Vector patrón aumentados:
| 0 | 0 | 1 | 1 |
| 0 | 1 | 1 | 1 |
| 1 | 0 | 1 | -1 |
| 1 | 1 | 1 | -1 |
Solución:
Al ver qué salida se espera, se puede intuir que la función de decisión es algo así como:
Graficamos las entradas y salidas para visualizar la separación de clases:
Por lo tanto, se puede usar la regla de actualización para cada patrón de entrenamiento:
-
Para el primer patrón con salida esperada :
- Usando la función de activación , se obtiene (incorrecto porque debe ser 1)
- Calculando el error
- Actualización de pesos:
-
Para el segundo patrón con salida esperada :
- (correcto)
- No hay error, por lo que no se actualizan los pesos.
-
Para el tercer patrón con salida esperada :
- (incorrecto porque debe ser -1)
- Calculando el error
- Actualización de pesos:
-
Para el cuarto patrón con salida esperada :
- (correcto)
- No hay error, por lo que no se actualizan los pesos.
Por lo tanto los pesos finales son , , y la función de decisión es:
Ahora, llevándolo a Rust, se puede implementar el perceptrón de la siguiente manera:
fn perceptron(x: &[f64], w: &[f64], b: f64) -> u8 {
let z: f64 = x.iter().zip(w.iter()).map(|(xi, wi)| xi * wi).sum::<f64>() + b;
if z > 0.0 { 1 } else { 0 }
}
fn main() {
let mut w = [0.0, 0.0, 0.0];
let mut b = 0.0;
let alpha = 0.5;
let training_data = [
([0.0, 0.0, 1.0], 1),
([0.0, 1.0, 1.0], 1),
([1.0, 0.0, 1.0], -1),
([1.0, 1.0, 1.0], -1),
];
for (x, y) in &training_data {
let y_hat = perceptron(x, &w, b);
let error = *y as f64 - y_hat as f64;
for i in 0..w.len() {
w[i] += alpha * error * x[i];
}
b += alpha * error;
}
println!("Pesos finales: {:?}", w);
println!("Sesgo final: {}", b);
}Si graficamos los casos, sabiendo que es el bias (y este por lo general no se representa en la gráfica), se puede observar que las entradas son linealmente separables, y por lo tanto el perceptrón converge a una solución que clasifica correctamente los patrones de entrenamiento.
El gran problema: el XOR
En 1969, Marvin Minsky y Seymour Papert publicaron un libro titulado Perceptrons donde demostraron que un perceptrón no puede resolver el problema XOR. Algo curioso, ya que en electrónica digital el XOR es ni más ni menos que una de las compuertas más importantes, y es la base de la aritmética binaria.
| XOR | ||
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
¿Por qué? Porque XOR no es linealmente separable, y por eso grafiqué el caso anterior, donde si te das cuenta, la representación gráfica del perceptrón es una línea recta, y para el caso de XOR, no existe una sola línea recta que separe los casos esperados y .
Pero de forma intuitiva dirías: pues grafiquemos dos líneas rectas, y con eso se resuelve el problema. Te podría decir que sí, pero no, la idea en general es colocar en cascada los perceptrones y utilizar una función de activación diferenciable.
Por ende, se empezó a utilizar funciones de activación no lineales, como la sigmoide, tanh o ReLU, que permiten a las redes neuronales aprender representaciones más complejas y resolver problemas no linealmente separables como XOR.
| Función | Fórmula | Cuándo usar |
|---|---|---|
| Sigmoide | Probabilidades binarias (salida) | |
| Tanh | Capas ocultas (cayó en desuso) | |
| ReLU | Estándar en capas ocultas hoy | |
| Softmax | Clasificación multiclase (salida) |
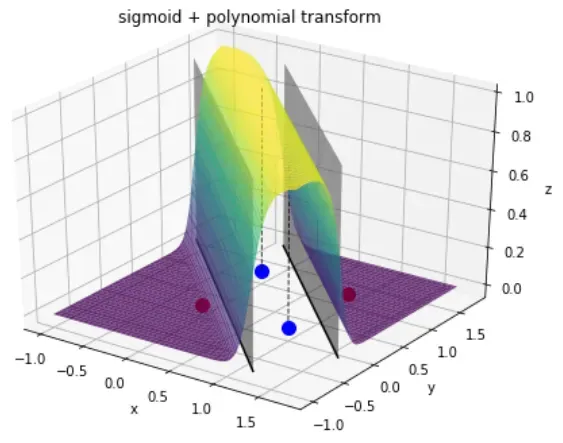
ReLU domina porque es barata de calcular y mitiga el problema del vanishing gradient.
Ahora ponte a pensar cuantas capas, pesos y clases usaran los modelos mas actuales, y dentro de cada capa, cuántos perceptrones habrá. La cantidad de parámetros que se ajustan en un modelo como GPT-4 es del orden de los billones, lo que significa que hay billones de perceptrones trabajando juntos para generar texto coherente.
@welchlabs The Perceptron, Part 3.
♬ original sound - Welch Labs
Backpropagation: cómo aprenden las redes profundas
El truco que destrabó todo en los 80 (Rumelhart, Hinton y Williams, 1986) fue backpropagation: una forma eficiente de calcular cómo cada peso de la red contribuye al error final, usando la regla de la cadena del cálculo diferencial.
A grandes rasgos:
- Forward pass: la entrada atraviesa la red y produce una predicción.
- Se calcula el error (función de pérdida) entre predicción y valor real.
- Backward pass: el error se propaga hacia atrás, capa por capa, repartiendo “culpa” entre los pesos.
- Cada peso se ajusta con gradient descent:
Repite millones de veces, y la red converge.
Esta es la magia: el mismo algoritmo que enseña a un MLP a clasificar dígitos es el que entrena a GPT-4. Solo cambian la escala, los datos y la arquitectura.
De perceptrones a transformers
Las redes modernas son perceptrones con esteroides arquitectónicos:
- CNN (Convolutional Neural Networks): perceptrones que comparten pesos para detectar patrones locales en imágenes.
- RNN / LSTM: perceptrones con memoria, para secuencias.
- Transformers: perceptrones combinados con un mecanismo de atención que pondera dinámicamente qué partes de la entrada importan más. Esta es la base de los LLMs.
A pesar de todas estas evoluciones, dentro de cada bloque de un transformer hay perceptrones haciendo su trabajo de siempre: multiplicar entradas por pesos, sumar un sesgo, aplicar una activación.
Conclusiones y Reflexiones finales
Se puede decir que el perceptrón es el ladrillo en esta construcción gigante llamada inteligencia artificial. Sin él, no tendríamos redes neuronales profundas, ni transformers, ni LLMs. Es el concepto fundamental que nos permite entender cómo las máquinas pueden “aprender” a partir de datos.
Esta es una primera parte de una serie de artículos donde compartiré la exploración de las redes neuronales aplicadas a la visión por computador, además estare compartiendo la creación de aplicaciones opensource y comerciales haciendo uso de modelos CNN y RNN (no apis, no mcps).
Esto debido a que el enfoque se ha centrado en consumir servicios de tipo MCPs o APIs de Claude, Gemini o ChatGPT, pero la creación de modelos propios se ha ido deteriorando, mucho hype y poco sentido común, el objetivo es gastar menos en tokens, y aprovechar la computación local, además de entender a fondo cómo funcionan estas tecnologías.
Si quieres aprender conmigo a crear tus propios modelos, o entender a fondo cómo funcionan, te invito a seguir esta serie de artículos donde desglosaremos cada componente de las redes neuronales, desde el perceptrón hasta los transformers, y veremos cómo aplicarlos en casos reales.
Referencias
- Rosenblatt, F. (1957). The Perceptron: A Perceiving and Recognizing Automaton. Cornell Aeronautical Laboratory, Report No. 85-460-1.
- Rosenblatt, F. (1958). The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain. Psychological Review.
- Minsky, M. & Papert, S. (1969). Perceptrons: An Introduction to Computational Geometry. MIT Press.
- Rumelhart, D., Hinton, G. & Williams, R. (1986). Learning representations by back-propagating errors. Nature.
- Goodfellow, I., Bengio, Y. & Courville, A. (2016). Deep Learning. MIT Press.
- Pajares, G. & de la Cruz, J. M. Visión por Computador: Imágenes digitales y aplicaciones. Ra-Ma.
- Nielsen, M. Neural Networks and Deep Learning — libro online gratuito.
- 3Blue1Brown. Serie sobre redes neuronales — explicación visual recomendada.
- MIT OpenCourseWare. HST.951J — Medical Decision Support: The Perceptron.
- MIT OpenCourseWare. 15.075J — Statistical Thinking and Data Analysis: Mean Squared Error.
- Pereira, L. (2021). Solving XOR with a Single Perceptron. Medium.
- The New Yorker (1958). Rival — Rosenblatt y el Perceptron.
- OpenAI (2026). Introducing ChatGPT Images 2.0.
#Inteligencia Artificial, #Redes Neuronales, #Machine Learning, #Deep Learning, #Perceptrón, #Claude, #Transformers, #Backpropagation, #XOR,